Dans ce TP, nous allons passer en revue les différentes étapes pour
faire un word embeddings à l'aide de BERT de Google.
Un peu d'histoire
L'année 2018 a été une année de percée dans le domaine du NLP.
L'apprentissage par transfert, en particulier des modèles comme ELMO
d'Allen AI, Open-GPT d'OpenAI et BERT de Google, a permis aux chercheurs
de pulvériser de nombreux benchmarks avec un ajustement minimal
spécifique à la tâche et a fourni au reste de la communauté du NLP des
modèles pré-entraînés qui pourraient facilement (avec moins de données
et moins de temps de calcul) être affinés et mis en œuvre pour produire
des résultats à la pointe de la technologie. Malheureusement, la théorie
et l'application pratique de ces modèles puissants sont encore mal
comprises par les personnes qui débutent dans le domaine du NLP et même
par certains praticiens expérimentés
C'est quoi BERT ?
BERT (Bidirectional Encoder Representations from Transformers),
publié fin 2018, est le modèle que nous utiliserons dans ce TP
d'introduction à l'utilisation des modèles d'apprentissage par transfert
en NLP. BERT est une architecture neuronale pré-entraînée des
représentations du langage qui a été utilisée pour créer des modèles que
les praticiens du NLP peuvent ensuite télécharger et utiliser (quand
c'est open source). Vous pouvez utiliser ces modèles pour extraire des
caractéristiques linguistiques de haute qualité à partir de vos données
textuelles, ou vous pouvez faire une fine-tuning de ces modèles sur une
tâche spécifique (classification, extractions d'information,réponse à
des questions, etc.) avec vos propres données.
Pourquoi un embeddings via BERT ?
Dans ce tutoriel, nous utiliserons BERT pour extraire des features, à
savoir des vecteurs d'embeddings de mots et de phrases, à partir de
données textuelles. Que pouvons-nous faire avec ces vecteurs
d'embeddings de mots et de phrases ? On peut les utiliser pout toute
tâche d'apprentissage.
Deuxièmement, et c'est peut-être le point le plus important, ces
vecteurs sont utilisés comme entrées (vecteur de variables explicatives
) dans des modèles d'apprentissage. Dans le passé, les mots ont été
représentés par codage disjonctif complet (one-hot encoding), soit, de
manière plus utile, comme embeddings de mots par modèles neuronaux tels
que Word2Vec ou Fasttext. BERT offre un avantage par rapport à des
modèles comme Word2Vec, car alors que chaque mot a une représentation
fixe dans Word2Vec, quel que soit le contexte dans lequel il apparaît,
BERT produit des représentations de mots qui sont dynamiquement
informées par les mots qui les entourent. Par exemple, si l'on considère
deux phrases :
Word2Vec would produce the same word embedding for the word "bank" in
both sentences, while under BERT the word embedding for "bank" would be
different for each sentence. Aside from capturing obvious differences
like polysemy, the context-informed word embeddings capture other forms
of information that result in more accurate feature representations,
which in turn results in better model performance.
Word2Vec produirait le même embedding pour le mot « banque » dans les
deux phrases, alors qu'avec BERT, l'embedding pour « banque » serait
différent pour chaque phrase. Outre la prise en compte de différences
évidentes telles que la polysémie, l'embedding des mots en fonction du
contexte permet de saisir d'autres formes d'informations qui se
traduisent par des représentations plus précises, ce qui se traduit par
une meilleure performance des modèles d'apprentissage.
From an educational standpoint, a close examination of BERT word
embeddings is a good way to get your feet wet with BERT and its family
of transfer learning models, and sets us up with some practical
knowledge and context to better understand the inner details of the
model in later tutorials.
D'un point de vue pédagogique, un examen approfondi des embeddings de
BERT est un bon moyen de se familiariser avec BERT et son utilisation
pour l'apprentissage par transfert.
1. Charger le modèle pré-entraîné BERT
Installation de l'interface pytorch pour BERT via le dépôt Hugging
Face. (Cette bibliothèque contient des interfaces pour d'autres modèles
de langage pré-entraînés comme GPT et GPT-2 d'OpenAI).
Sur Google Colab, on doit installer cette bibliothèque à chaque
reconnection.
!pip install transformers
Nous allons importer pytorch, le modèle pré-entraîné BERT et son
tokenizer.
Nous n'allons pas expliquer le modèle en détail dans ce tp. Il s'agit
du modèle pré-entraîné publié par Google qui a fonctionné pendant de
très nombreuses heures sur Wikipédia et Book Corpus, un ensemble
de données contenant +10 000 livres de différents genres. Ce modèle est
responsable (avec quelques modifications) d'avoir battu des benchmarks
NLP dans un grand nombre de tâches. Google a publié quelques variantes
des modèles BERT, mais celui que nous utiliserons ici est le plus petit
des deux tailles disponibles (« base » et « large ») et ignore
insensible à la casse (insensible aux majuscules et minuscules), d'où le
terme « uncased ».
transformers fournit un certain nombre de classes pour
appliquer BERT à différentes tâches (classification de tokens (jetons),
classification de textes, ...). Ici, nous utilisons le
BertModel de base qui n'a pas de tâche de sortie spécifique
- c'est un bon choix pour utiliser BERT juste pour extraire des
embeddings.
import torch
from transformers import BertTokenizer, BertModel
# OPTIONAL: if you want to have more information on what's happening, activate the logger as follows
import logging
#logging.basicConfig(level=logging.INFO)
import matplotlib.pyplot as plt
%matplotlib inline
# Load pre-trained model tokenizer (vocabulary)
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
2.1. Jetons spéciaux (special Tokens)
BERT peut prendre en entrée une ou deux phrases, et utilise le token
spécial [SEP] pour les différencier. Le token
[CLS] apparaît toujours au début du texte et est spécifique
aux tâches de classification.
Les deux tokens sont toujours requis, cependant, même si
nous n'avons qu'une seule phrase, et même si nous n'utilisons pas
l'outil BERT pour la classification. C'est ainsi que BERT a été
pré-entraîné, et c'est donc ce que BERT s'attend à voir.
2 phrases en entrée:
[CLS] The man went to the store. [SEP] He bought a gallon of milk.
1 phrase en entrée:
[CLS] The man went to the store. [SEP]
2.2. Opération de "Tokenization" (découpage en jetons de base)
BERT fournit son propre tokenizer, que nous avons importé ci-dessus.
Voyons comment il traite la phrase ci-dessous.
text = "Here is the sentence I want embeddings for."
marked_text = "[CLS] " + text + " [SEP]"
# Tokeniser la phrase à l'aide du tokenizer de BERT.
tokenized_text = tokenizer.tokenize(marked_text)
# Affichage des jetons.
print (tokenized_text)
Le mot « embeddings » est représenté (ou découpé en jetons) comme
suit:
['em', '##bed', '##ding', '##s']
Le mot original a été divisé en sous-mots et caractères plus petits.
Les deux signes ## qui précèdent certains de ces sous-mots sont
simplement la façon dont notre tokenizer indique que ce sous-mot ou ce
caractère fait partie d'un mot plus large et qu'il est précédé d'un
autre sous-mot. Ainsi, par exemple, le jeton « ##bed » est distinct du
jeton « bed » ; le premier est utilisé chaque fois que le sous-mot « bed
» apparaît dans un mot plus large et le second est utilisé explicitement
lorsque le jeton correspondant au mot «bed (lit)» apparaît.
Why does it look this way? This is because the BERT tokenizer was
created with a WordPiece model. This model greedily creates a fixed-size
vocabulary of individual characters, subwords, and words that best fits
our language data. Since the vocabulary limit size of our BERT tokenizer
model is 30,000, the WordPiece model generated a vocabulary that
contains all English characters plus the ~30,000 most common words and
subwords found in the English language corpus the model is trained on.
This vocabulary contains four things:
de quoi s'agit-il ? C'est parce que le tokenizer de BERT a été créé
avec un modèle WordPiece. Ce modèle crée un vocabulaire de taille fixe
composé de caractères individuels, de sous-mots et de mots qui
correspondent le mieux à nos données linguistiques. Étant donné que la
taille limite du vocabulaire de notre tokenizer BERT est de 30 000, le
modèle WordPiece a généré un vocabulaire qui contient tous les
caractères anglais ainsi que les ~30 000 mots et sous-mots les plus
courants trouvés dans le corpus de langue anglaise sur lequel le modèle
est entraîné. Ce vocabulaire contient quatre éléments :
Mots entiers
Sous-mots apparaissant au début d'un mot ou isolément (« em »
comme dans « embeddings » se voit attribuer le même vecteur que la
séquence autonome de caractères « em » comme dans « go get em »
)
Les sous-mots ne se trouvant pas au début d'un mot, qui sont
précédés de « ## » pour indiquer ce cas.
Caractères individuels
Pour tokeniser un mot dans le cadre de ce modèle, le tokenizer
vérifie d'abord si le mot entier figure dans le vocabulaire. Si ce n'est
pas le cas, il tente de décomposer le mot en sous-mots les plus larges
possibles contenus dans le vocabulaire et, en dernier recours, il
décompose le mot en caractères individuels. Notez que, pour cette
raison, nous pouvons toujours représenter un mot comme étant, au
minimum, la collection de ses caractères individuels.
Par conséquent, plutôt que d'assigner les mots hors vocabulaire à un
jeton fourre-tout tel que « OOV » ou « UNK », les mots qui ne font pas
partie du vocabulaire sont décomposés en sous-mots et en tokens de
caractères pour lesquels nous pouvons ensuite générer des
embeddings.
Ainsi, plutôt que d'attribuer « embeddings » et tout autre mot hors
vocabulaire à un jeton de vocabulaire inconnu surchargé, nous le
divisons en sous-mots ['em', '##bed', '##ding', '##s'] qui conserveront
une partie de la signification contextuelle du mot d'origine. Nous
pouvons même faire la moyenne de ces vecteurs d'embedding de sous-mots
pour générer un vecteur approximatif pour le mot d'origine.
(Pour plus d'information sur WordPiece, voiroriginal
paper et échanges google Neural Machine Translation
System.)
Voici quelques exemples de tokens du vocabulaire. Les tokens
commençant par ## sont des sous-mots ou des caractères individuels.
list(tokenizer.vocab.keys())[5000:5020]
Après avoir divisé le texte en jetons, nous devons convertir la
phrase d'une liste de chaînes de caractères en une liste d'indices de
vocabulaire.
À partir de là, nous utiliserons l'exemple de phrase ci-dessous, qui
contient deux occurrences du mot «bank» avec des significations
différentes.
# Un autre exemple de phrase avec différentes significations du mot "bank"
text = "After stealing money from the bank vault, the bank robber was seen " \
"fishing on the Mississippi river bank."
# Ajouter les deux tokens spéciaux
marked_text = "[CLS] " + text + " [SEP]"
# Diviser la phrase en tokens.
tokenized_text = tokenizer.tokenize(marked_text)
# Récupérer les indices des tokens dans le vocabulaire.
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
# Affichage des mots avec les indices.
for tup in zip(tokenized_text, indexed_tokens):
print('{:<12} {:>6,}'.format(tup[0], tup[1]))
2.3. Identification d'une phrase (segment ID)
Pour chaque token dans "tokenized_text", nous devons spécifier à
quelle phrase il appartient : la phrase 0 (une série de 0) ou la phrase
1 (une série de 1). Pour nos besoins, les entrées de phrases simples ne
nécessitent qu'une série de 1, nous créerons donc un vecteur de 1 pour
chaque token de notre phrase d'entrée.
Si on veut traiter deux phrases, attribuez un 0 à chaque mot de la
première phrase ainsi qu'au jeton « [SEP] », et un 1 à tous les jetons
de la deuxième phrase.
# Marquer chacun des 22 tokens comme appartenant à la phrase "1".
segments_ids = [1] * len(tokenized_text)
print(segments_ids)
3. Récupérer les embeddings
3.1. Faire tourner BERT sur nos bouts de textes
Nous allons convertir nos données en tenseurs torch et appeler le
modèle BERT. L'interface BERT PyTorch exige que les données soient dans
des tenseurs torch plutôt que dans des listes Python, nous convertissons
donc les listes ici - cela ne change pas la forme ou les données.
# convertir en PyTorch tensors
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
L'appel à from_pretrained va récupérer le modèle.
Lorsque nous chargeons bert-base-uncased, nous voyons la
définition du modèle affichée. Le modèle est un réseau neuronal profond
avec 12 couches ! L'explication des couches et de leurs fonctions
n'entre pas dans le cadre de ce TP.
model.eval() place notre modèle en mode évaluation par opposition au
mode entraînement. Dans ce cas, le mode évaluation désactive la
régularisation dropout qui est utilisée lors de l'apprentissage.
# charger le modèle pré-entraîné (les poids)
model = BertModel.from_pretrained('bert-base-uncased',
output_hidden_states = True, # Si le modèle renvoie tous les états cachés.
)
# Met le modèle en mode "evaluation", pour faire un passe-avant.
model.eval()
Evaluons BERT sur notre exemple, et récupérons les états cachés du
réseau !
torch.no_grad indique à PyTorch de ne pas construire
le graphe de calcul du gradient pendant cette passe-avant (puisque nous
n'exécuterons pas de rétro-prop ici) -- cela réduit simplement la
consommation de mémoire et accélère un peu les choses.
# Passer le texte dans le réseau de neurones BERT, et collecter tous les états cachés
# des 12 couches.
with torch.no_grad():
outputs = model(tokens_tensor, segments_tensors)
# Evaluating the model will return a different number of objects based on
# how it's configured in the `from_pretrained` call earlier. In this case,
# becase we set `output_hidden_states = True`, the third item will be the
# hidden states from all layers. See the documentation for more details:
# https://huggingface.co/transformers/model_doc/bert.html#bertmodel
hidden_states = outputs[2]
3.2. Comprendre la sortie de la passe-avant
L'ensemble des états cachés de ce modèle, stockés dans l'objet
hidden_states, est un peu vertigineux. Cet objet a quatre
dimensions, dans l'ordre suivant
- Le numéro de la couche (13 couches)
- Le numéro de lot (1 phrase)
- Le nombre de mots / tokens (22 tokens dans notre phrase)
- L'unité cachée / la dimension de l'embeddings (768 features)
13 couches alors que BERT n'en a pas seulement 12 ? C'est 13 parce
que le premier élément est l'embedding d'entrée, le reste étant les
sorties de chacune des 12 couches de BERT.
Bilan : 219648 valeurs uniques pour représenter notre phrase !
La deuxième dimension, la taille du lot, est utilisée lorsque
plusieurs phrases sont soumises au modèle en même temps ; ici, nous
n'avons qu'une seule phrase d'exemple.
print ("Nombre de couches :", len(hidden_states), " (embeddings initial + 12 couches de BERT)")
layer_i = 0
print ("Nombre de lots:", len(hidden_states[layer_i]))
batch_i = 0
print ("Nombre de tokens:", len(hidden_states[layer_i][batch_i]))
token_i = 0
print ("Nombre d'unités cachées:", len(hidden_states[layer_i][batch_i][token_i]))
On remarque que les valeurs renvoyées par toutes les couches et tous
les jetons, la majorité des valeurs se situant entre [-2, 2] et un petit
nombre de valeurs autour de -10.
# Pout le token 5 dans notre phrase, regarder les données de la couche 5.
token_i = 5
layer_i = 5
vec = hidden_states[layer_i][batch_i][token_i]
# Plot the values as a histogram to show their distribution.
plt.figure(figsize=(10,10))
plt.hist(vec, bins=200)
plt.show()
Le regroupement des valeurs par couche est logique pour le modèle,
mais pour nos besoins, nous voulons qu'elles soient regroupées par
token.
Dimensions actuelles :
[# layers, # batches, # tokens, # features]
Dimensions souhaitées :
[# tokens, # layers, # features]
PyTorch offre la fonction permute pour réarranger
facilement les dimensions d'un tenseur.
Cependant, la première dimension est actuellement une liste Python
!
# `hidden_states` est une liste Python.
print(' Type of hidden_states: ', type(hidden_states))
# chaque couche dans la liste est un tenseur torch.
print('Taille du tenseur de chaque couche: ', hidden_states[0].size())
Combinons les couches pour obtenir un grand tenseur.
# on regroupe les tenseurs pour toutes les couches. On utilise la méthode `stack`
# ça donne de nouvelles dimensions de tenseur.
token_embeddings = torch.stack(hidden_states, dim=0)
token_embeddings.size()
Supprimons la dimension "lots" puisque nous n'en avons pas
besoin.
# Supprimer la dimension 1 des "batches".
token_embeddings = torch.squeeze(token_embeddings, dim=1)
token_embeddings.size()
Enfin, nous pouvons alterner les dimensions "layers" et "tokens" avec
permute.
# alterner les dimensions
token_embeddings = token_embeddings.permute(1,0,2)
token_embeddings.size()
3.3. Création de vecteurs de représentation des mots et phrases à
partir des hidden states
Maintenant, que faisons-nous avec ces états cachés ? Nous aimerions
obtenir des vecteurs individuels pour chacun de nos tokens, ou peut-être
une représentation vectorielle unique de la phrase entière, mais pour
chaque token de notre entrée, nous disposons de 13 vecteurs distincts,
chacun d'une longueur de 768.
Pour obtenir les vecteurs individuels, nous devons combiner certains
des vecteurs des couches... mais quelle couche ou combinaison de couches
fournit la meilleure représentation ?
Malheureusement, il n'y a pas de réponse simple et unique... Essayons
quelques approches raisonnables.
Les Word Vectors
Pour se donner quelques exemples, testons deux approches.
Premièrement, appliquer un concatenate les 4
dernières couches, nous donnent un seul vecteur par token. Chaque
vecteur sera de taille 4 x 768 = 3072.
# Stores the token vectors, with shape [22 x 3,072]
token_vecs_cat = []
# `token_embeddings` is a [22 x 12 x 768] tensor.
# For each token in the sentence...
for token in token_embeddings:
# `token` is a [12 x 768] tensor
# Concatenate the vectors (that is, append them together) from the last
# four layers.
# Each layer vector is 768 values, so `cat_vec` is length 3,072.
cat_vec = torch.cat((token[-1], token[-2], token[-3], token[-4]), dim=0)
# Use `cat_vec` to represent `token`.
token_vecs_cat.append(cat_vec)
print ('Shape is: %d x %d' % (len(token_vecs_cat), len(token_vecs_cat[0])))
Une autre méthode consiste à créer des word vectors en faisant la
somme des 4 dernières.
# Stores the token vectors, with shape [22 x 768]
token_vecs_sum = []
# `token_embeddings` is a [22 x 12 x 768] tensor.
# For each token in the sentence...
for token in token_embeddings:
# `token` is a [12 x 768] tensor
# Sum the vectors from the last four layers.
sum_vec = torch.sum(token[-4:], dim=0)
# Use `sum_vec` to represent `token`.
token_vecs_sum.append(sum_vec)
print ('Shape is: %d x %d' % (len(token_vecs_sum), len(token_vecs_sum[0])))
Pour obtenir un vecteur unique pour l'ensemble de notre phrase, nous
disposons de plusieurs stratégies en fonction de notre objectif, mais
une approche simple consiste à faire la moyenne de l'avant-dernière
couche cachée de chaque token, ce qui produit un vecteur unique d'une
longueur de 768.
# `hidden_states` has shape [13 x 1 x 22 x 768]
# `token_vecs` is a tensor with shape [22 x 768]
token_vecs = hidden_states[-2][0]
# Calculate the average of all 22 token vectors.
sentence_embedding = torch.mean(token_vecs, dim=0)
print ("embedding de notre phrase est un vecteur de la forme:", sentence_embedding.size())
3.4. Confirmation des vecteurs dépendant du contexte
To confirm that the value of these vectors are in fact contextually
dependent, let's look at the different instances of the word "bank" in
our example sentence:
"After stealing money from the bank vault, the
bank robber was seen fishing on the Mississippi
river bank."
Let's find the index of those three instances of the word "bank" in
the example sentence.
Pour confirmer que la valeur de ces vecteurs dépend effectivement du
contexte, examinons les différentes occurrences du mot « bank » dans
notre phrase d'exemple :
"After stealing money from the bank vault, the
bank robber was seen fishing on the Mississippi
river bank."
Trouvons l'indice de ces trois occurrences du mot « bank » dans la
phrase d'exemple.
for i, token_str in enumerate(tokenized_text):
print (i, token_str)
3 occurrences à 6, 10, and 19.
Pour cette analyse, nous utiliserons les vecteurs de mots que nous
avons créés en additionnant les quatre dernières couches. Nous pouvons
essayer d'imprimer leurs vecteurs pour les comparer.
print('Les 5 premières composantes du vecteur pour chaque occurrence de "bank".')
print('')
print("bank vault ", str(token_vecs_sum[6][:5]))
print("bank robber ", str(token_vecs_sum[10][:5]))
print("river bank ", str(token_vecs_sum[19][:5]))
Nous pouvons constater que les valeurs diffèrent, mais calculons la
similarité cosinus entre les vecteurs pour effectuer une comparaison
plus précise.
from scipy.spatial.distance import cosine
# "bank robber" vs "river bank" (different meanings).
diff_bank = 1 - cosine(token_vecs_sum[10], token_vecs_sum[19])
# "bank robber" vs "bank vault" (same meaning).
same_bank = 1 - cosine(token_vecs_sum[10], token_vecs_sum[6])
print('valeur de la similarité dans le cas (bank pour banque dans les deux cas): %.2f' % same_bank)
print('valeur de la similarité dans le cas (bank pour banque et rive ): %.2f' % diff_bank)
3.5. Stratégie de pooling et choix des couches
Ci-dessous quelques ressources supplémentaires pour explorer ce
sujet.
Auteurs de BERT
Les auteurs de l'étude BERT ont testé des stratégies d'intégration de
mots en introduisant différentes combinaisons de vecteurs comme
caractéristiques d'entrée dans une BiLSTM utilisée pour une tâche de
reconnaissance d'entités nommées et en observant les scores F1
obtenus.
(Image du blog Jay Allamar)
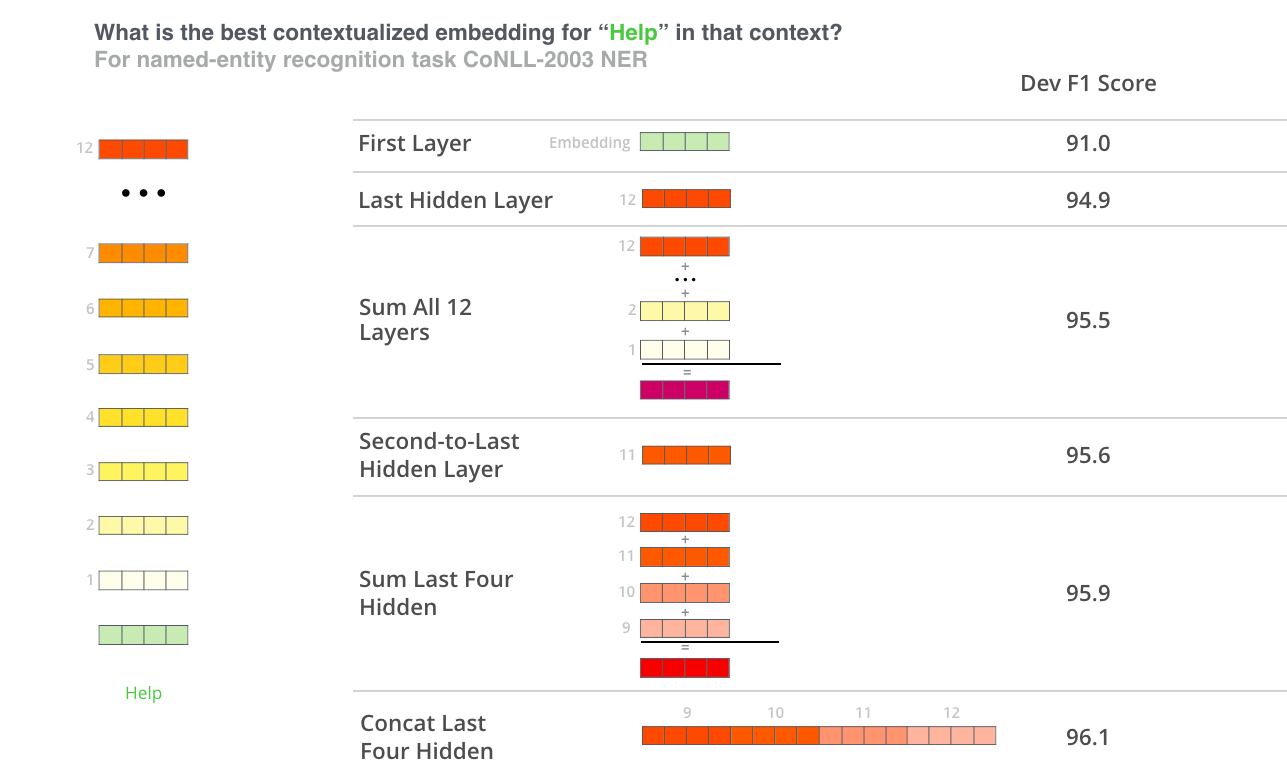
Bien que la concaténation des quatre dernières couches ait produit
les meilleurs résultats pour cette tâche spécifique, de nombreuses
autres méthodes arrivent juste derrière et, en général, il est conseillé
de tester différentes versions pour votre application spécifique : les
résultats peuvent varier.
Ceci est partiellement démontré par le fait que les différentes
couches de BERT encodent des types d'informations très différents, de
sorte que la stratégie de mise en commun appropriée changera en fonction
de l'application parce que les différentes couches encodent des types
d'informations différents.
BERT-as-service de Han Xiao
Han Xiao a créé un projet open-source nommé bert-as-service
sur GitHub qui a pour but de créer des embeddings de mots pour votre
texte en utilisant BERT. Han a expérimenté différentes approches pour
combiner ces embeddings, et a partagé quelques conclusions et
discussions sur la page
FAQ du projet.
bert-as-service, par défaut, utilise les résultats de
l'avant-dernière couche du modèle.
On peut résumer le point de vue de Han par ce qui suit :
Les embeddings commencent dans la première couche sans aucune
information contextuelle (c'est-à-dire que la signification de
l'embedding initial « bank » n'est pas spécifique à la rive ou à la
banque financière).
Au fur et à mesure que les embeddings se déplacent dans le
réseau, ils acquièrent de plus en plus d'informations contextuelles à
chaque couche.
Cependant, à mesure qu'on approche de la dernière couche, on
commence à recueillir des informations spécifiques aux tâches de
pré-entraînement de BERT (le « modèle du langage masqué » (MLM) et la «
prédiction de la phrase suivante » (NSP)).
- Ce que nous voulons, ce sont des embeddings qui encodent bien le
sens du mot...
- BERT est motivé pour faire cela, mais il est également motivé pour
encoder tout ce qui pourrait l'aider à déterminer ce qu'est un mot
manquant (MLM), ou si la deuxième phrase vient après la première
(NSP).
L'avant-dernière couche est ce que Han a décidé comme étant un
seuil raisonnable.
Il convient de noter que bien que le [CLS] agisse comme
une « représentation agrégée » pour les tâches de classification, ce
n'est pas le meilleur choix pour un vecteur d'embedding de phrases de
grande qualité. Selon
Jacob Devlin, auteur de BERT : «I'm not sure what these vectors are,
since BERT does not generate meaningful sentence vectors. It seems that
this is is doing average pooling over the word tokens to get a sentence
vector, but we never suggested that this will generate meaningful
sentence representations. »
(Toutefois, le token [CLS] devient pertinant si le modèle a été
affiné, lorsque la dernière couche cachée de ce jeton est utilisée comme
« vecteur de phrase » pour la classification des séquences).
4.2. Les mots hors vocabulaire
Pour les mots hors vocabulaire qui sont composés de
plusieurs embeddings au niveau de la phrase et du caractère, un autre
problème se pose : comment récupérer au mieux cet embedding. La solution
la plus simple consiste à faire la moyenne des embeddings (une solution
sur laquelle s'appuient des modèles d'embeddings similaires avec des
vocabulaires de sous-mots comme fasttext), mais la sommation des
embeddings de sous-mots et la simple prise de l'embedding du dernier
token (notons que les vecteurs sont sensibles au contexte) sont d'autres
stratégies acceptables.
4.3. Métriques de similarité
Il convient de noter que les comparaisons de
similarité au niveau des mots ne sont pas appropriées avec les
embeddings BERT car ces embeddings dépendent du contexte, ce qui
signifie que le vecteur de mot change en fonction de la phrase dans
laquelle il apparaît. Cela permet des choses merveilleuses comme la
polysémie, de sorte que, par exemple, votre représentation encode la
rive « bank » et non une institution financière « bank », mais rend les
comparaisons directes de similarité mot à mot moins valables. Toutefois,
pour les embeddings de phrases, les comparaisons de similarité restent
valables, de sorte qu'il est possible d'interroger, par exemple, une
seule phrase par rapport à un ensemble d'autres phrases afin de trouver
la plus similaire. Selon la métrique de similarité utilisée, les valeurs
de similarité résultantes seront moins informatives que le classement
relatif des résultats de similarité, car de nombreuses métriques de
similarité font des hypothèses sur l'espace vectoriel (dimensions à
pondération égale, par exemple) qui ne sont pas valables pour notre
espace vectoriel à 768 dimensions.
4.4. Implémentations
Vous pouvez utiliser ce comme base de votre propre application pour
extraire les caractéristiques BERT du texte. Cependant, des
implémentations très appréciées de pytorch
qui le font pour vous, existent. En outre, bert-as-a-service
est un excellent outil conçu spécifiquement pour exécuter cette tâche
avec de hautes performances, et c'est celui que je recommanderais.
L'auteur a pris grand soin de l'implémentation de l'outil et fournit une
excellente documentation (dont une partie a été utilisée pour aider à
créer ce TP) pour aider les utilisateurs à comprendre les détails plus
nuancés auxquels l'utilisateur est confronté, comme la gestion des
ressources et la stratégie de pooling.